Introduction to linear regression#
Batter up#
The movie Moneyball focuses on the “quest for the secret of success in baseball”. It follows a low-budget team, the Oakland Athletics, who believed that underused statistics, such as a player’s ability to get on base, betterpredict the ability to score runs than typical statistics like home runs, RBIs (runs batted in), and batting average. Obtaining players who excelled in these underused statistics turned out to be much more affordable for the team.
In this lab we’ll be looking at data from all 30 Major League Baseball teams and examining the linear relationship between runs scored in a season and a number of other player statistics. Our aim will be to summarize these relationships both graphically and numerically in order to find which variable, if any, helps us best predict a team’s runs scored in a season.
The data#
Let’s load up the data for the 2011 season.
import warnings
warnings.filterwarnings("ignore")
import numpy as np
import pandas as pd
import io
import requests
df_url = 'https://raw.githubusercontent.com/akmand/datasets/master/openintro/mlb11.csv'
url_content = requests.get(df_url, verify=False).content
mlb11 = pd.read_csv(io.StringIO(url_content.decode('utf-8')))
In addition to runs scored, there are seven traditionally used variables in the data set: at-bats, hits, home runs, batting average, strikeouts, stolen bases, and wins. There are also three newer variables: on-base percentage, slugging percentage, and on-base plus slugging. For the first portion of the analysis we’ll consider the seven traditional variables. At the end of the lab, you’ll work with the newer variables on your own.
Exercise 1
What type of plot would you use to display the relationship betweenruns and one of the other numerical variables? Plot this relationship using the variable at_bats as the predictor. Does the relationship look linear? If you knew a team's at_bats, would you be comfortable using a linear model to predict the number of runs?
If the relationship looks linear, we can quantify the strength of the relationship with the correlation coefficient.
mlb11['runs'].corr(mlb11['at_bats'])
0.6106270467206687
Sum of squared residuals#
Think back to the way that we described the distribution of a single variable. Recall that we discussed characteristics such as center, spread, and shape. It’s also useful to be able to describe the relationship of two numerical variables, such as runs and at_bats above.
Exercise 2
Looking at your plot from the previous exercise, describe the relationship between these two variables. Make sure to discuss the form, direction, and strength of the relationship as well as any unusual observations.Recall that the difference between the observed values and the values predicted by the line are called residuals. Note that the data set has 30 observations in total, hence there are 30 residuals.
\({e}\)i = \({y}\)i−\(\bar{y}\)i#
To visualize the residuals of a linear regression, we can use residplot() function from seaborn:
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
plt.style.use('ggplot')
plt.rcParams['figure.figsize'] = (10,5)
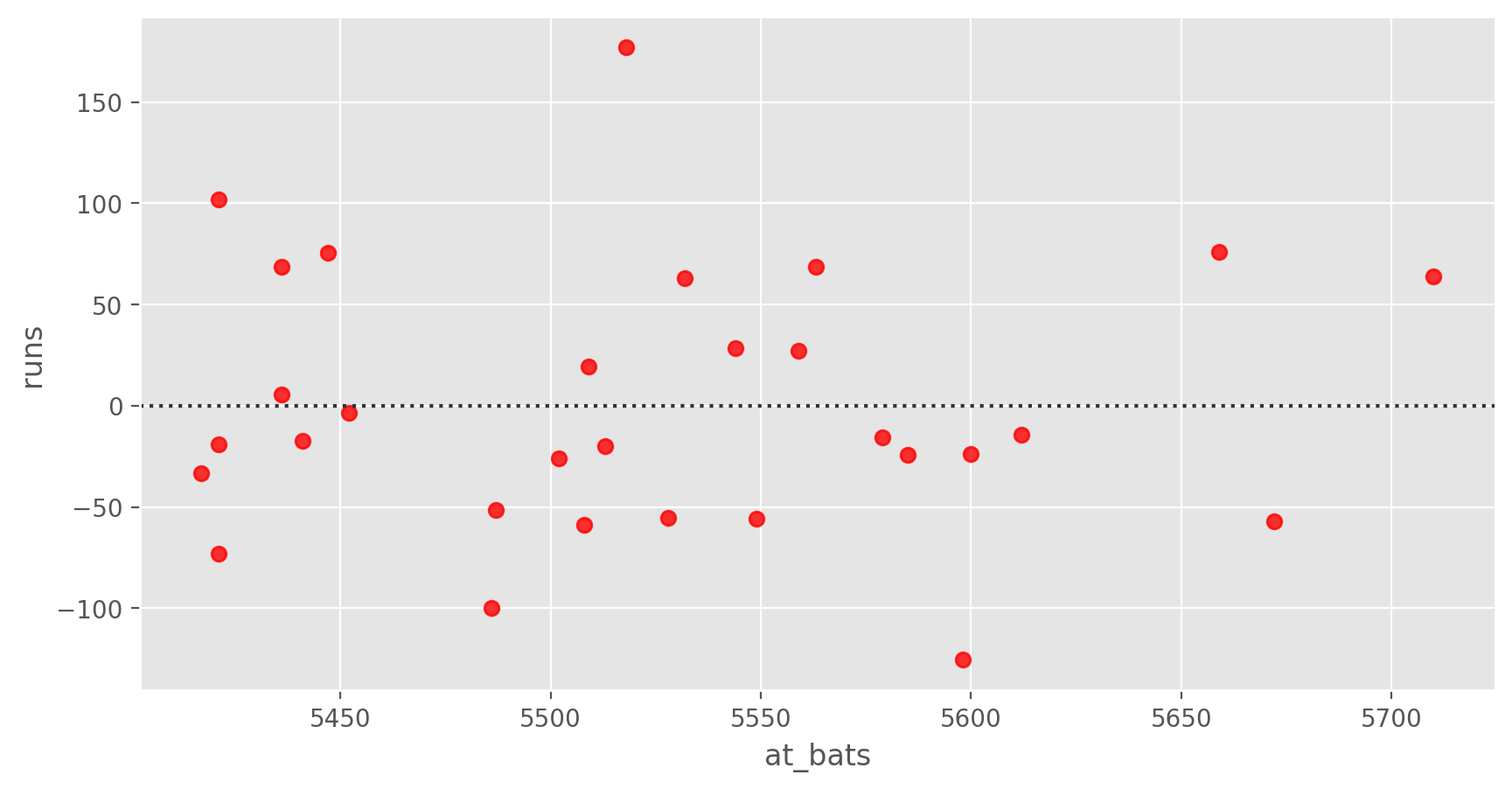
sns.residplot(x='at_bats', y='runs', data=mlb11, color='red')
plt.show();
The linear model#
In order to determine the best fit line we can use `statsmodel’, a very useful module for the estimation of many different statistical models, as well as for conducting statistical tests, and statistical data exploration.
import statsmodels.api as sm
formula_string = "runs ~ at_bats"
model = sm.formula.ols(formula = formula_string, data = mlb11)
model_fitted = model.fit()
print(model_fitted.summary())
OLS Regression Results
==============================================================================
Dep. Variable: runs R-squared: 0.373
Model: OLS Adj. R-squared: 0.350
Method: Least Squares F-statistic: 16.65
Date: Tue, 23 Jul 2024 Prob (F-statistic): 0.000339
Time: 00:32:22 Log-Likelihood: -167.44
No. Observations: 30 AIC: 338.9
Df Residuals: 28 BIC: 341.7
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept -2789.2429 853.696 -3.267 0.003 -4537.959 -1040.526
at_bats 0.6305 0.155 4.080 0.000 0.314 0.947
==============================================================================
Omnibus: 2.579 Durbin-Watson: 1.524
Prob(Omnibus): 0.275 Jarque-Bera (JB): 1.559
Skew: 0.544 Prob(JB): 0.459
Kurtosis: 3.252 Cond. No. 3.89e+05
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 3.89e+05. This might indicate that there are
strong multicollinearity or other numerical problems.
Let’s print the intercept and slope values.
print('Intercept =', model_fitted.params[0])
print('Slope =', model_fitted.params[1])
Intercept = -2789.242885442251
Slope = 0.6305499928382827
Knowing the intercept and slope, we can write down the least squares regression line for the linear model:
\({y}\) = - 2789.2429 + 0.6305 x \({atbats}\)#
One last piece of information we will discuss from the summary output is the Multiple R-squared, or more simply, \({R}\)2. The \({R}\)2 value represents the proportion of variability in the response variable that is explained by the explanatory variable. For this model, 37.3% of the variability in runs is explained by at-bats.
print('R-squared =', model_fitted.rsquared)
R-squared = 0.37286539018680565
Exercise 3
Fit a new model that useshomeruns to predict runs. Using the estimates from the Python output, write the equation of the regression line. What does the slope tell us in the context of the relationship between success of a team and its home runs?
Prediction and prediction errors#
Just as we used the mean and standard deviation to summarize a single variable, we can summarize the relationship between these two variables by finding the line that best follows their association. Let’s plot at_bats and runs on a scatter plot.
x = mlb11['at_bats']
y = mlb11['runs']
y_pred = model_fitted.predict(x)
plt.scatter(mlb11['at_bats'], mlb11['runs'])
plt.plot(x, y_pred, color = 'orange')
plt.show();
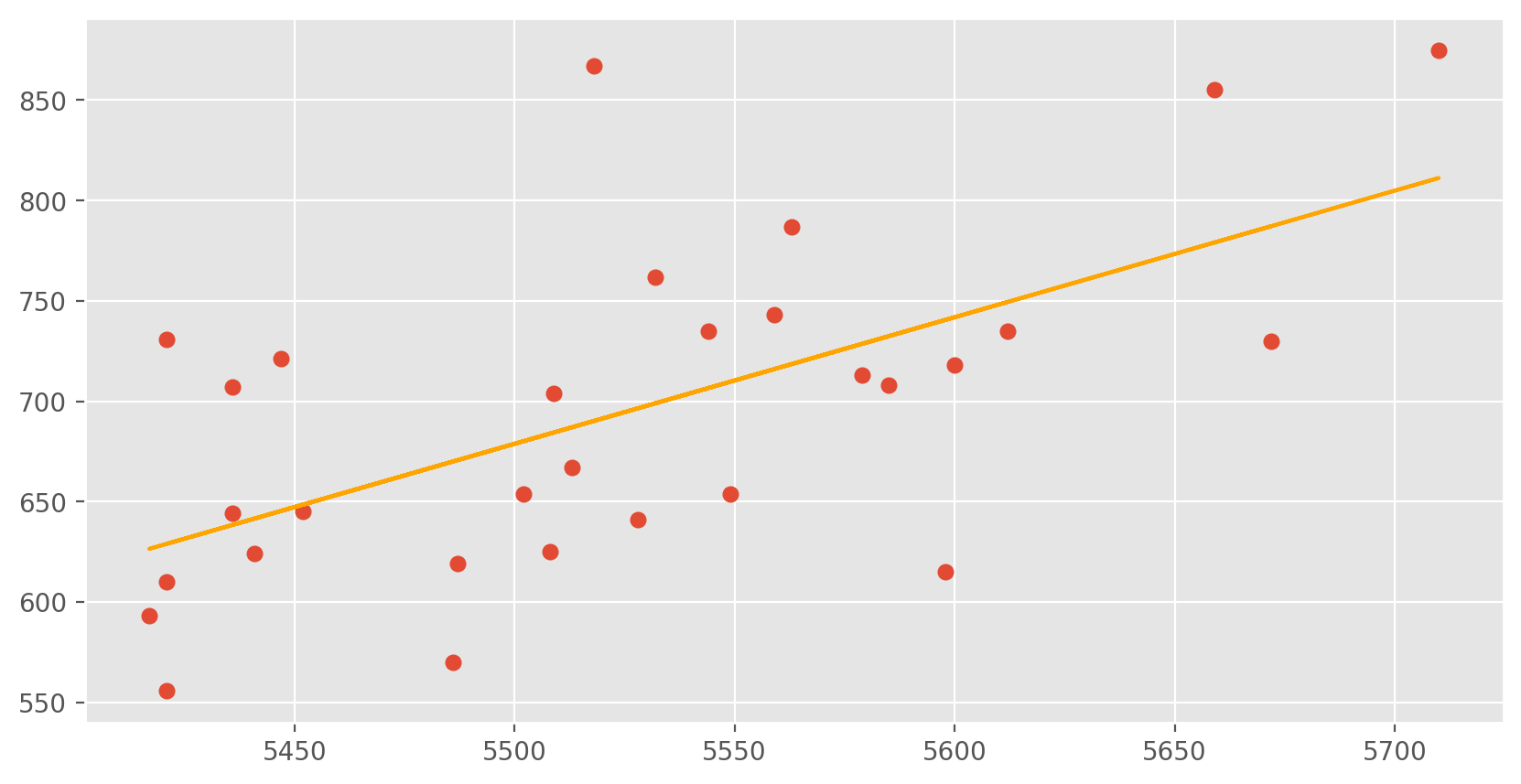
Exercise 4
If a team manager saw the least squares regression line and not the actual data, how many runs would he or she predict for a team with 5,578 at-bats? Is this an overestimate or an underestimate, and by how much? In other words, what is the residual for this prediction?Model diagnostics#
To assess whether the linear model is reliable, we need to check for (1) linearity, (2) nearly normal residuals, and (3) constant variability.
Linearity: You already checked if the relationship between runs and at-bats is linear using a scatterplot. We should also verify this condition with a plot of the residuals vs. at-bats.
import seaborn as sns
sns.residplot(x='at_bats', y='runs', data=mlb11, color='red')
plt.xlabel('at_bats', fontsize = 16)
plt.ylabel('residuals', fontsize = 16)
plt.show();
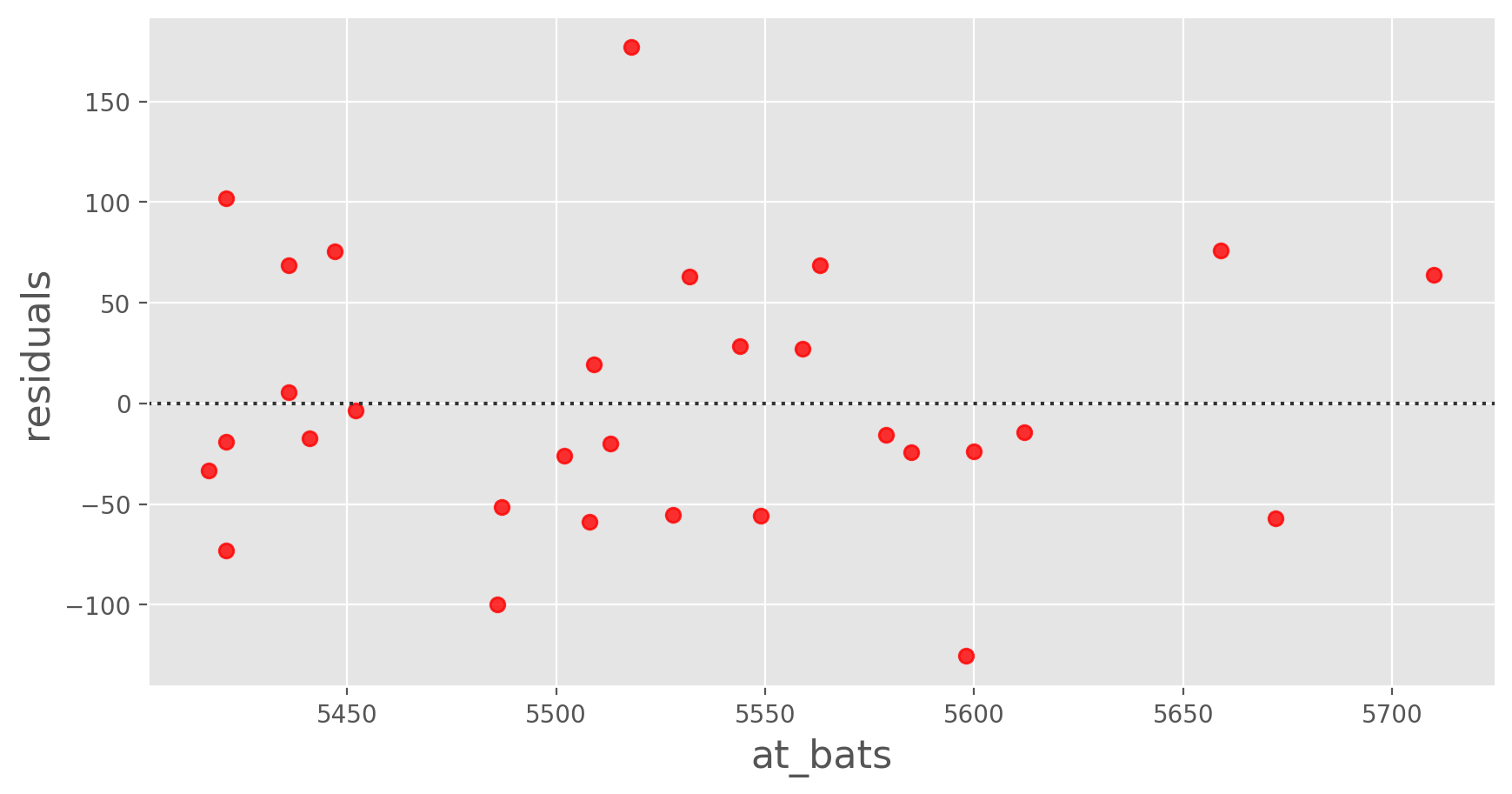
Exercise 5
Is there any apparent pattern in the residuals plot? What does this indicate about the linearity of the relationship between runs and at-bats?Nearly normal residuals: To check this condition, we can look at a histogram.
residuals = (y - y_pred)
plt.hist(residuals, bins = 8)
plt.show();
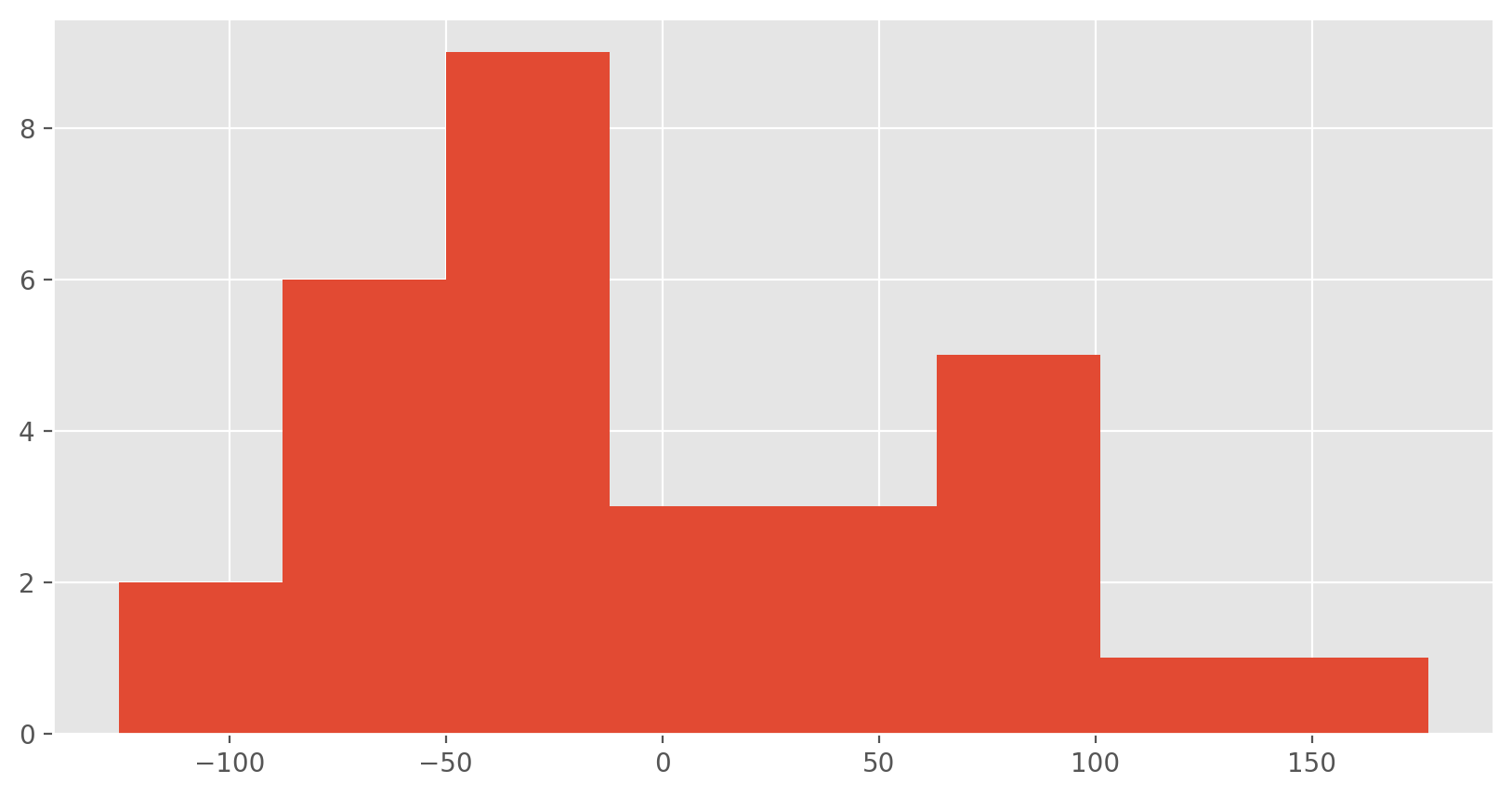
or a normal probability plot of the residuals.
from scipy.stats import probplot
probplot(residuals, plot = plt)
plt.show();
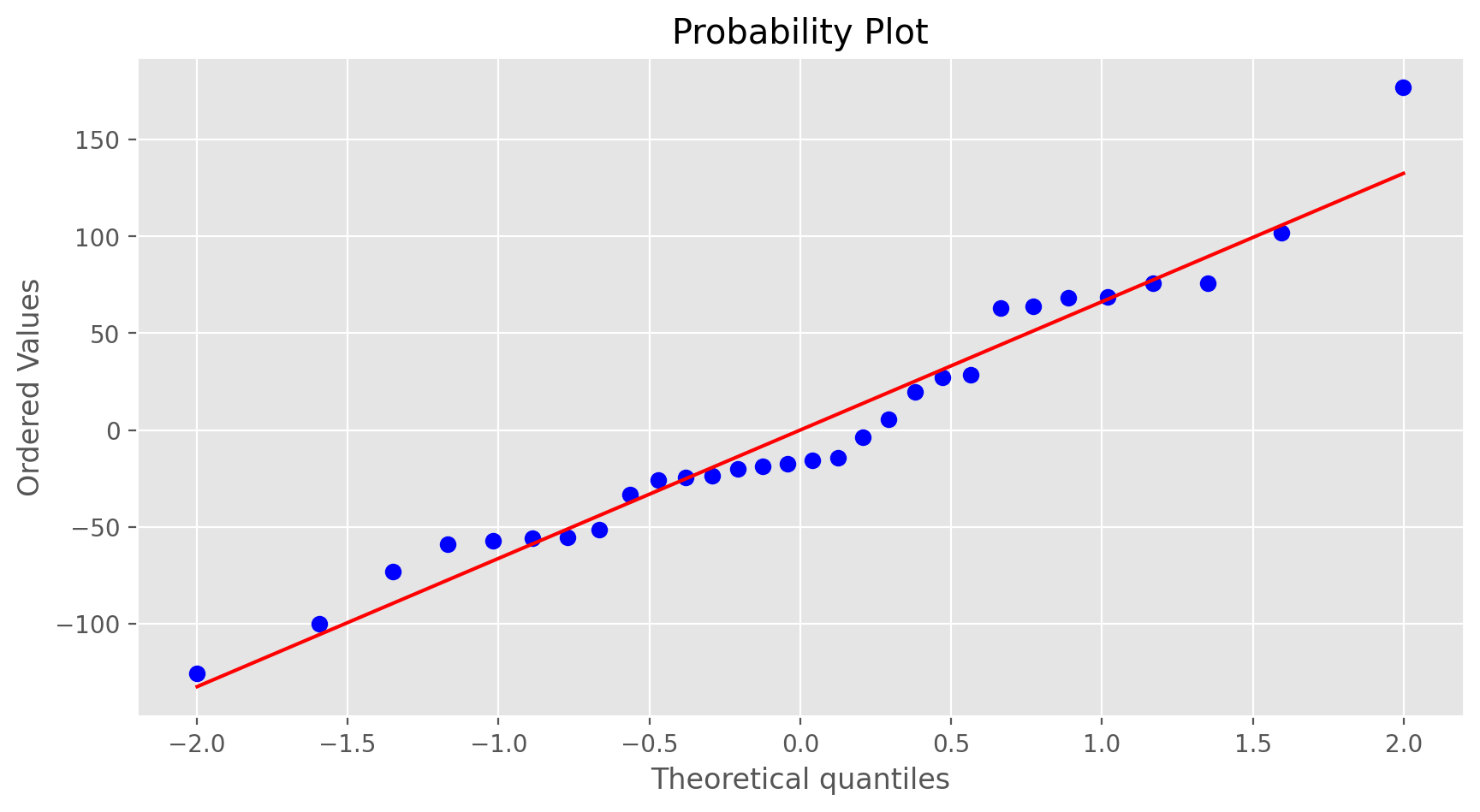
Exercise 6
Based on the histogram and the normal probability plot, does the nearly normal residuals condition appear to be met?Constant variability:
Exercise 7
Based on the plot in (1), does the constant variability condition appear to be met?On Your Own#
- Choose another traditional variable from
mlb11that you think might be a good predictor ofruns. Produce a scatterplot of the two variables and fit a linear model. At a glance, does there seem to be a linear relationship? - How does this relationship compare to the relationship between
runsandat_bats? Use the R squared values from the two model summaries to compare. Does your variable seem to predictrunsbetter thanat_bats? How can you tell? - Now that you can summarize the linear relationship between two variables, investigate the relationships between
runsand each of the other five traditional variables. Which variable best predictsruns? Support your conclusion using the graphical and numerical methods we've discussed (for the sake of conciseness, only include output for the best variable, not all five). - Now examine the three newer variables. These are the statistics used by the author of Moneyball to predict a teams success. In general, are they more or less effective at predicting runs that the old variables? Explain using appropriate graphical and numerical evidence. Of all ten variables we've analyzed, which seems to be the best predictor of
runs? Using the limited (or not so limited) information you know about these baseball statistics, does your result make sense? - Check the model diagnostics for the regression model with the variable you decided was the best predictor for
runs