Predicting Income Status#
The objective of this case study is to fit and compare three different binary classifiers to predict whether an individual earns more than USD 50,000 (50K) or less in a year using the 1994 US Census Data sourced from the UCI Machine Learning Repository (Lichman, 2013). The descriptive features include 4 numeric and 7 nominal categorical features. The target feature has two classes defined as “<=50K” and “>50K” respectively. The full dataset contains about 45K observations.
This report is organized as follows:
Section 2 (Overview) outlines our methodology.
Section 3 (Data Preparation) summarizes the data preparation process and our model evaluation strategy.
Section 4 (Hyper-parameter Tuning) describes the hyper-parameter tuning process for each classification algorithm.
Section 5 (Performance Comparison) presents model performance comparison results.
Section 6 (Limitations) discusses a limitations of our approach and possible solutions.
Section 7 (Summary) provides a brief summary of our work in this project.
Compiled from a Jupyter Notebook, this report contains both narratives and the Python code used throughout the project.
Overview #
Methodology#
We consider the following (binary) classifiers to predict the target feature:
K-Nearest Neighbors (KNN),
Decision trees (DT), and
Naive Bayes (NB).
Our modeling strategy begins by transforming the full dataset cleaned in Phase I. This transformation includes encoding categorical descriptive features as numerical and then scaling of the descriptive features. We first randomly sample 20K rows from the full dataset and then split this sample into training and test sets with a 70:30 ratio. This way, our training data has 14K rows and test data has 6K rows. To be clear, our terminology here is that
The 14K rows of data used during the hyper-parameter tuning phase is called the training data.
The 6K rows of data used during the performance comparison phase is called the test data.
Before fitting a particular classifier on the training data, we select the best features using the powerful Random Forest Importance method inside a pipeline. We consider 10, 20, and the full set of features (with 41 features) after encoding of categorical features. Using feature selection together with hyper-parameter search inside a single pipeline, we conduct a 5-fold stratified cross-validation to fine-tune hyper-parameters of each classifier using area under curve (AUC) as the performance metric. We build each model using parallel processing with “-2” cores. Since the target feature has more individuals earning less than USD 50K in 1994 (unbalanced target class issue), stratification is crucial to ensure that each validation set has the same proportion of classes as in the original dataset. We also examine sensitivity of each model with respect to its hyper-parameters during the search.
Classifiers with the best set of hyper-parameter values as identified via grid search using the training data are called tuned classifiers. Once we identify the three tuned classifiers (with the best hyper-parameter values), we “fit” them on the test data using 10-fold cross-validation in a paired fashion and we perform paired t-tests to see if any performance difference is statistically significant. In addition, we compare the classifiers with respect to their recall scores and confusion matrices on the test data.
Data Preparation #
Loading Dataset#
We load the dataset from the Cloud. Below we set the seed to a particular value at the beginning of this notebook so that our results can be repeated later on.
import warnings
warnings.filterwarnings("ignore")
import numpy as np
import pandas as pd
import io
import requests
# so that we can see all the columns
pd.set_option('display.max_columns', None)
# how to read a csv file from a github account
url_name = 'https://raw.githubusercontent.com/akmand/datasets/master/us_census_income_data_clean.csv'
url_content = requests.get(url_name, verify=False).content
dataset = pd.read_csv(io.StringIO(url_content.decode('utf-8')))
print(dataset.shape)
dataset.columns.values
(45222, 12)
array(['age', 'workclass', 'education_num', 'marital_status',
'occupation', 'relationship', 'race', 'gender', 'hours_per_week',
'native_country', 'capital', 'income_status'], dtype=object)
The full data has 45,222 observations. It has 11 descriptive features and the “income_status” target feature.
Checking for Missing Values#
Let’s make sure we do not have any missing values.
dataset.isna().sum()
age 0
workclass 0
education_num 0
marital_status 0
occupation 0
relationship 0
race 0
gender 0
hours_per_week 0
native_country 0
capital 0
income_status 0
dtype: int64
Let’s have a look at 5 randomly selected rows in this raw dataset.
dataset.sample(n=5, random_state=999)
| age | workclass | education_num | marital_status | occupation | relationship | race | gender | hours_per_week | native_country | capital | income_status | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 29270 | 40 | private | 10 | never_married | exec_managerial | unmarried | white | female | 40 | united_states | 0 | <=50k |
| 25610 | 24 | state_gov | 13 | never_married | prof_specialty | not_in_family | white | female | 20 | united_states | 0 | <=50k |
| 19125 | 38 | self_emp_not_inc | 9 | married_civ_spouse | handlers_cleaners | husband | white | male | 40 | united_states | 0 | >50k |
| 43423 | 43 | self_emp_not_inc | 9 | married_civ_spouse | adm_clerical | wife | white | female | 15 | united_states | 0 | <=50k |
| 14464 | 37 | local_gov | 15 | married_civ_spouse | prof_specialty | husband | white | male | 60 | united_states | 0 | >50k |
Summary Statistics#
The summary statistics for the full data are shown below.
dataset.describe(include='all')
| age | workclass | education_num | marital_status | occupation | relationship | race | gender | hours_per_week | native_country | capital | income_status | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 45222.000000 | 45222 | 45222.000000 | 45222 | 45222 | 45222 | 45222 | 45222 | 45222.000000 | 45222 | 45222.000000 | 45222 |
| unique | NaN | 7 | NaN | 7 | 14 | 6 | 2 | 2 | NaN | 2 | NaN | 2 |
| top | NaN | private | NaN | married_civ_spouse | craft_repair | husband | white | male | NaN | united_states | NaN | <=50k |
| freq | NaN | 33307 | NaN | 21055 | 6020 | 18666 | 38903 | 30527 | NaN | 41292 | NaN | 34014 |
| mean | 38.547941 | NaN | 10.118460 | NaN | NaN | NaN | NaN | NaN | 40.938017 | NaN | 1012.834925 | NaN |
| std | 13.217870 | NaN | 2.552881 | NaN | NaN | NaN | NaN | NaN | 12.007508 | NaN | 7530.315380 | NaN |
| min | 17.000000 | NaN | 1.000000 | NaN | NaN | NaN | NaN | NaN | 1.000000 | NaN | -4356.000000 | NaN |
| 25% | 28.000000 | NaN | 9.000000 | NaN | NaN | NaN | NaN | NaN | 40.000000 | NaN | 0.000000 | NaN |
| 50% | 37.000000 | NaN | 10.000000 | NaN | NaN | NaN | NaN | NaN | 40.000000 | NaN | 0.000000 | NaN |
| 75% | 47.000000 | NaN | 13.000000 | NaN | NaN | NaN | NaN | NaN | 45.000000 | NaN | 0.000000 | NaN |
| max | 90.000000 | NaN | 16.000000 | NaN | NaN | NaN | NaN | NaN | 99.000000 | NaN | 99999.000000 | NaN |
Encoding Categorical Features#
Prior to modeling, it is essential to encode all categorical features (both the target feature and the descriptive features) into a set of numerical features.
Encoding the Target Feature#
We remove the “income_status” feature from the full dataset and call it “target”. The rest of the features are the descriptive features which we call “Data”.
Data = dataset.drop(columns='income_status')
target = dataset['income_status']
target.value_counts()
income_status
<=50k 34014
>50k 11208
Name: count, dtype: int64
Let’s encode the target feature so that the positive class is “>50K” and it is encoded as “1”.
target = target.replace({'<=50K': 0, '>50K': 1})
target.value_counts()
income_status
<=50k 34014
>50k 11208
Name: count, dtype: int64
As a side note, we observe that the classes are not quite balanced.
Encoding Categorical Descriptive Features#
Since all of the descriptive features appear to be nominal, we perform one-hot-encoding. Furthermore, since we plan on conducting feature selection, we define \(q\) dummy variables for a categorical descriptive variable with \(q\) levels. The exception here is that when a categorical descriptive feature has only two levels, we define a single dummy variable. Let’s extract the list of categorical descriptive features.
categorical_cols = Data.columns[Data.dtypes==object].tolist()
Before any transformation, the categorical features are as follows.
categorical_cols
['workclass',
'marital_status',
'occupation',
'relationship',
'race',
'gender',
'native_country']
The coding operation is shown below. For each two-level categorical variable, we set the drop_first option to True to encode the variable into a single column of 0 or 1. Next, we apply the get_dummies() function for the regular one-hot encoding for categorical features with more than 2 levels.
for col in categorical_cols:
if (Data[col].nunique() == 2):
Data[col] = pd.get_dummies(Data[col], drop_first=True)
# use one-hot-encoding for categorical features with >2 levels
Data = pd.get_dummies(Data)
After encoding, the feature set has the following columns.
Data.columns
Index(['age', 'education_num', 'race', 'gender', 'hours_per_week',
'native_country', 'capital', 'workclass_federal_gov',
'workclass_local_gov', 'workclass_private', 'workclass_self_emp_inc',
'workclass_self_emp_not_inc', 'workclass_state_gov',
'workclass_without_pay', 'marital_status_divorced',
'marital_status_married_af_spouse', 'marital_status_married_civ_spouse',
'marital_status_married_spouse_absent', 'marital_status_never_married',
'marital_status_separated', 'marital_status_widowed',
'occupation_adm_clerical', 'occupation_armed_forces',
'occupation_craft_repair', 'occupation_exec_managerial',
'occupation_farming_fishing', 'occupation_handlers_cleaners',
'occupation_machine_op_inspct', 'occupation_other_service',
'occupation_priv_house_serv', 'occupation_prof_specialty',
'occupation_protective_serv', 'occupation_sales',
'occupation_tech_support', 'occupation_transport_moving',
'relationship_husband', 'relationship_not_in_family',
'relationship_other_relative', 'relationship_own_child',
'relationship_unmarried', 'relationship_wife'],
dtype='object')
Data.sample(5, random_state=999)
| age | education_num | race | gender | hours_per_week | native_country | capital | workclass_federal_gov | workclass_local_gov | workclass_private | workclass_self_emp_inc | workclass_self_emp_not_inc | workclass_state_gov | workclass_without_pay | marital_status_divorced | marital_status_married_af_spouse | marital_status_married_civ_spouse | marital_status_married_spouse_absent | marital_status_never_married | marital_status_separated | marital_status_widowed | occupation_adm_clerical | occupation_armed_forces | occupation_craft_repair | occupation_exec_managerial | occupation_farming_fishing | occupation_handlers_cleaners | occupation_machine_op_inspct | occupation_other_service | occupation_priv_house_serv | occupation_prof_specialty | occupation_protective_serv | occupation_sales | occupation_tech_support | occupation_transport_moving | relationship_husband | relationship_not_in_family | relationship_other_relative | relationship_own_child | relationship_unmarried | relationship_wife | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 29270 | 40 | 10 | True | False | 40 | True | 0 | False | False | True | False | False | False | False | False | False | False | False | True | False | False | False | False | False | True | False | False | False | False | False | False | False | False | False | False | False | False | False | False | True | False |
| 25610 | 24 | 13 | True | False | 20 | True | 0 | False | False | False | False | False | True | False | False | False | False | False | True | False | False | False | False | False | False | False | False | False | False | False | True | False | False | False | False | False | True | False | False | False | False |
| 19125 | 38 | 9 | True | True | 40 | True | 0 | False | False | False | False | True | False | False | False | False | True | False | False | False | False | False | False | False | False | False | True | False | False | False | False | False | False | False | False | True | False | False | False | False | False |
| 43423 | 43 | 9 | True | False | 15 | True | 0 | False | False | False | False | True | False | False | False | False | True | False | False | False | False | True | False | False | False | False | False | False | False | False | False | False | False | False | False | False | False | False | False | False | True |
| 14464 | 37 | 15 | True | True | 60 | True | 0 | False | True | False | False | False | False | False | False | False | True | False | False | False | False | False | False | False | False | False | False | False | False | False | True | False | False | False | False | True | False | False | False | False | False |
Scaling of Features#
After encoding all the categorical features, we perform a min-max scaling of the descriptive features. But first we make a copy of the Data to keep track of column names.
from sklearn import preprocessing
Data_df = Data.copy()
Data_scaler = preprocessing.MinMaxScaler()
Data_scaler.fit(Data)
Data = Data_scaler.fit_transform(Data)
Let’s have another look at the descriptive features after scaling. Pay attention that the output of the scaler is a NumPy array, so all the column names are lost. That’s why we kept a copy of Data before scaling so that we can recover the column names below. We observe below that binary features are still kept as binary after the min-max scaling.
pd.DataFrame(Data, columns=Data_df.columns).sample(5, random_state=999)
| age | education_num | race | gender | hours_per_week | native_country | capital | workclass_federal_gov | workclass_local_gov | workclass_private | workclass_self_emp_inc | workclass_self_emp_not_inc | workclass_state_gov | workclass_without_pay | marital_status_divorced | marital_status_married_af_spouse | marital_status_married_civ_spouse | marital_status_married_spouse_absent | marital_status_never_married | marital_status_separated | marital_status_widowed | occupation_adm_clerical | occupation_armed_forces | occupation_craft_repair | occupation_exec_managerial | occupation_farming_fishing | occupation_handlers_cleaners | occupation_machine_op_inspct | occupation_other_service | occupation_priv_house_serv | occupation_prof_specialty | occupation_protective_serv | occupation_sales | occupation_tech_support | occupation_transport_moving | relationship_husband | relationship_not_in_family | relationship_other_relative | relationship_own_child | relationship_unmarried | relationship_wife | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 29270 | 0.315068 | 0.600000 | 1.0 | 0.0 | 0.397959 | 1.0 | 0.041742 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 25610 | 0.095890 | 0.800000 | 1.0 | 0.0 | 0.193878 | 1.0 | 0.041742 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 19125 | 0.287671 | 0.533333 | 1.0 | 1.0 | 0.397959 | 1.0 | 0.041742 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 43423 | 0.356164 | 0.533333 | 1.0 | 0.0 | 0.142857 | 1.0 | 0.041742 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 14464 | 0.273973 | 0.933333 | 1.0 | 1.0 | 0.602041 | 1.0 | 0.041742 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
Feature Selection & Ranking#
Let’s have a look at the most important 10 features as selected by Random Forest Importance (RFI) in the full dataset. This is for a quick ranking of the most relevant 10 features to gain some insight into the problem at hand. During the hyperparameter tuning phase, we will include RFI as part of the pipeline and we will search over 10, 20, and the full set of 41 features to determine which number of features works best with each classifier.
from sklearn.ensemble import RandomForestClassifier
num_features = 10
model_rfi = RandomForestClassifier(n_estimators=100)
model_rfi.fit(Data, target)
fs_indices_rfi = np.argsort(model_rfi.feature_importances_)[::-1][0:num_features]
best_features_rfi = Data_df.columns[fs_indices_rfi].values
best_features_rfi
array(['age', 'capital', 'education_num', 'hours_per_week',
'relationship_husband', 'marital_status_married_civ_spouse',
'marital_status_never_married', 'occupation_exec_managerial',
'occupation_prof_specialty', 'race'], dtype=object)
feature_importances_rfi = model_rfi.feature_importances_[fs_indices_rfi]
feature_importances_rfi
array([0.23631035, 0.14501304, 0.13922436, 0.11586573, 0.07099669,
0.06915243, 0.02195376, 0.02005248, 0.01518717, 0.01230276])
Let’s visualize these importances.
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
plt.style.use("seaborn-v0_8")
def plot_imp(best_features, scores, method_name):
plt.barh(best_features, scores)
plt.title(method_name + ' Feature Importances')
plt.xlabel("Importance")
plt.ylabel("Features")
plt.show()
plot_imp(best_features_rfi, feature_importances_rfi, 'Random Forest')
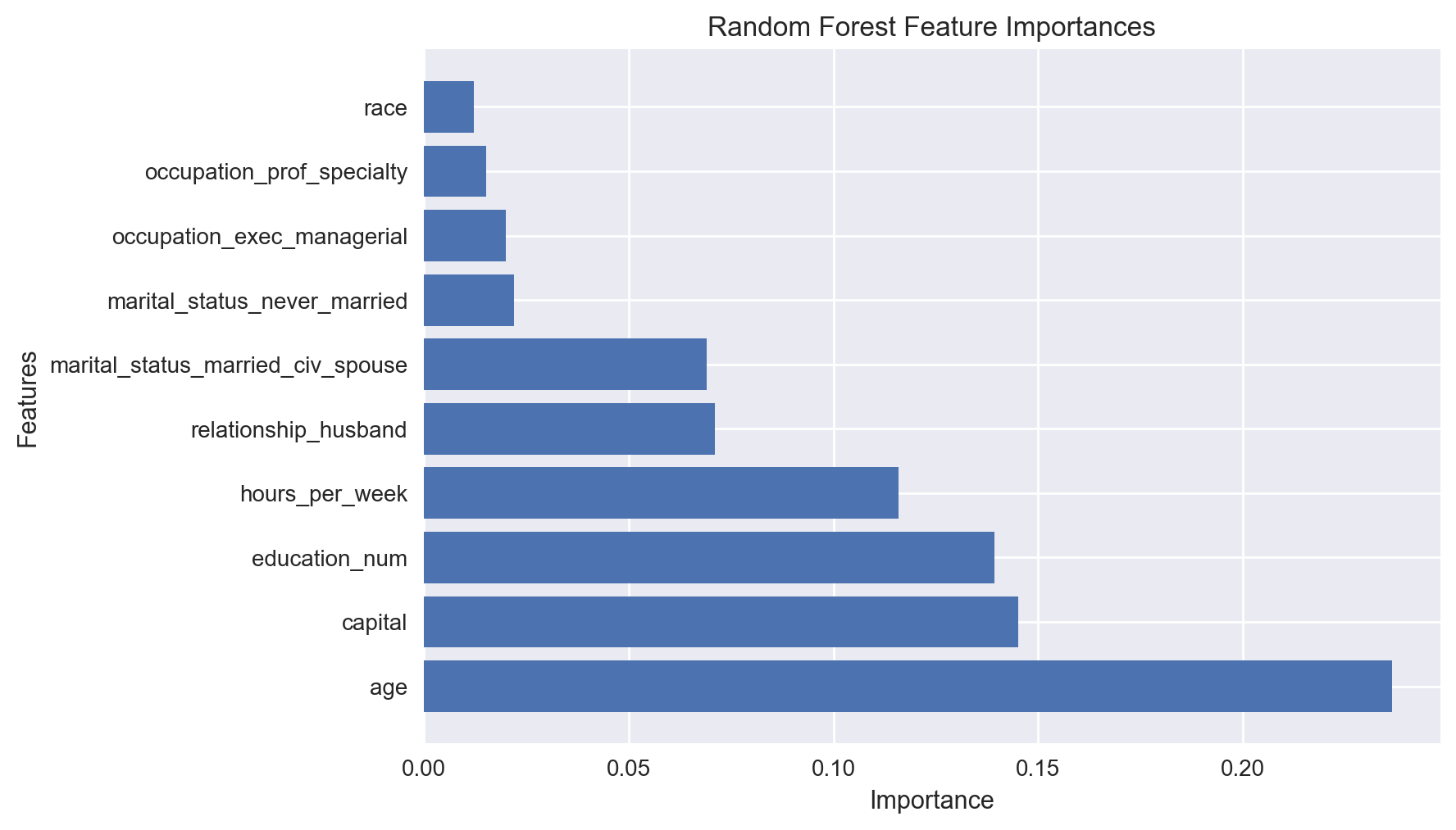
We observe that the most important feature is age, followed by capital, education, and hours per week.
Data Sampling & Train-Test Splitting#
The original dataset has more than 45K rows, which is a lot. So, we would like to work with a small sample here with 20K rows. Thus, we will do the following:
Randomly select 20K rows from the full dataset.
Split this sample into train and test partitions with a 70:30 ratio using stratification.
Pay attention here that we use values attribute to convert Pandas data frames to a NumPy array. You have to make absolutely sure that you NEVER pass Pandas data frames to Scikit-Learn functions!!! Sometimes it will work. But sometimes you will end up getting strange errors such as “invalid key” etc. Remember, Scikit-Learn works with NumPy arrays, not Pandas data frames.
n_samples = 20000
Data_sample = pd.DataFrame(Data).sample(n=n_samples, random_state=8).values
target_sample = pd.DataFrame(target).sample(n=n_samples, random_state=8).values
print(Data_sample.shape)
print(target_sample.shape)
(20000, 41)
(20000, 1)
from sklearn.model_selection import train_test_split
Data_sample_train, Data_sample_test, \
target_sample_train, target_sample_test = train_test_split(Data_sample, target_sample,
test_size = 0.3, random_state=999,
stratify = target_sample)
target_sample_test = target_sample_test.ravel()
print(Data_sample_train.shape)
print(Data_sample_test.shape)
(14000, 41)
(6000, 41)
Model Evaluation Strategy#
So, we will train and tune our models on 14K rows of training data and we will test them on 6K rows of test data.
For each model, we will use 5-fold stratified cross-validation evaluation method (without any repetitions for shorter run times) for hyperparameter tuning.
from sklearn.model_selection import StratifiedKFold, GridSearchCV
cv_method = StratifiedKFold(n_splits=5, shuffle=True, random_state=999)
Hyperparameter Tuning #
K-Nearest Neighbors (KNN)#
Using Pipeline, we stack feature selection and grid search for KNN hyperparameter tuning via cross-validation. We will use the same Pipeline methodology for NB and DT.
The KNN hyperparameters are as follows:
number of neighbors (
n_neighbors) andthe distance metric
p.
For feature selection, we use the powerful Random Forest Importance (RFI) method with 100 estimators. A trick here is that we need a bit of coding so that we can make RFI feature selection as part of the pipeline. For this reason, we define the custom RFIFeatureSelector() class
below to pass in RFI as a “step” to the pipeline.
from sklearn.base import BaseEstimator, TransformerMixin
# custom function for RFI feature selection inside a pipeline
# here we use n_estimators=100
class RFIFeatureSelector(BaseEstimator, TransformerMixin):
# class constructor
# make sure class attributes end with a "_"
# per scikit-learn convention to avoid errors
def __init__(self, n_features_=10):
self.n_features_ = n_features_
self.fs_indices_ = None
# override the fit function
def fit(self, X, y):
from sklearn.ensemble import RandomForestClassifier
from numpy import argsort
model_rfi = RandomForestClassifier(n_estimators=100)
model_rfi.fit(X, y)
self.fs_indices_ = argsort(model_rfi.feature_importances_)[::-1][0:self.n_features_]
return self
# override the transform function
def transform(self, X, y=None):
return X[:, self.fs_indices_]
from sklearn.pipeline import Pipeline
from sklearn.neighbors import KNeighborsClassifier
pipe_KNN = Pipeline(steps=[('rfi_fs', RFIFeatureSelector()),
('knn', KNeighborsClassifier())])
params_pipe_KNN = {'rfi_fs__n_features_': [10, 20, Data.shape[1]],
'knn__n_neighbors': [1, 5, 10, 15, 20],
'knn__p': [1, 2]}
gs_pipe_KNN = GridSearchCV(estimator=pipe_KNN,
param_grid=params_pipe_KNN,
cv=cv_method,
refit=True,
n_jobs=-2,
scoring='roc_auc',
verbose=1)
target_sample_train = target_sample_train.ravel() # to make a 1d array
gs_pipe_KNN.fit(Data_sample_train, target_sample_train);
Fitting 5 folds for each of 30 candidates, totalling 150 fits
gs_pipe_KNN.best_params_
{'knn__n_neighbors': 20, 'knn__p': 2, 'rfi_fs__n_features_': 10}
gs_pipe_KNN.best_score_
0.8734979888336427
We observe that the optimal KNN model has a mean AUC score of 0.871. The best performing KNN selected 10 features with 20 nearest neighbors and \(p=1\), which is the Manhattan distance.
Even though these are the best values, let’s have a look at the other combinations to see if the difference is rather significant or not. For this, we will make use of the function below to format the grid search outputs as a Pandas data frame.
# custom function to format the search results as a Pandas data frame
def get_search_results(gs):
def model_result(scores, params):
scores = {'mean_score': np.mean(scores),
'std_score': np.std(scores),
'min_score': np.min(scores),
'max_score': np.max(scores)}
return pd.Series({**params,**scores})
models = []
scores = []
for i in range(gs.n_splits_):
key = f"split{i}_test_score"
r = gs.cv_results_[key]
scores.append(r.reshape(-1,1))
all_scores = np.hstack(scores)
for p, s in zip(gs.cv_results_['params'], all_scores):
models.append((model_result(s, p)))
pipe_results = pd.concat(models, axis=1).T.sort_values(['mean_score'], ascending=False)
columns_first = ['mean_score', 'std_score', 'max_score', 'min_score']
columns = columns_first + [c for c in pipe_results.columns if c not in columns_first]
return pipe_results[columns]
results_KNN = get_search_results(gs_pipe_KNN)
results_KNN.head()
| mean_score | std_score | max_score | min_score | knn__n_neighbors | knn__p | rfi_fs__n_features_ | |
|---|---|---|---|---|---|---|---|
| 27 | 0.873498 | 0.005868 | 0.882791 | 0.866026 | 20.0 | 2.0 | 10.0 |
| 24 | 0.872979 | 0.006175 | 0.883804 | 0.865047 | 20.0 | 1.0 | 10.0 |
| 21 | 0.870450 | 0.005706 | 0.879929 | 0.863030 | 15.0 | 2.0 | 10.0 |
| 28 | 0.870217 | 0.002880 | 0.873596 | 0.866694 | 20.0 | 2.0 | 20.0 |
| 25 | 0.870150 | 0.003371 | 0.873714 | 0.865099 | 20.0 | 1.0 | 20.0 |
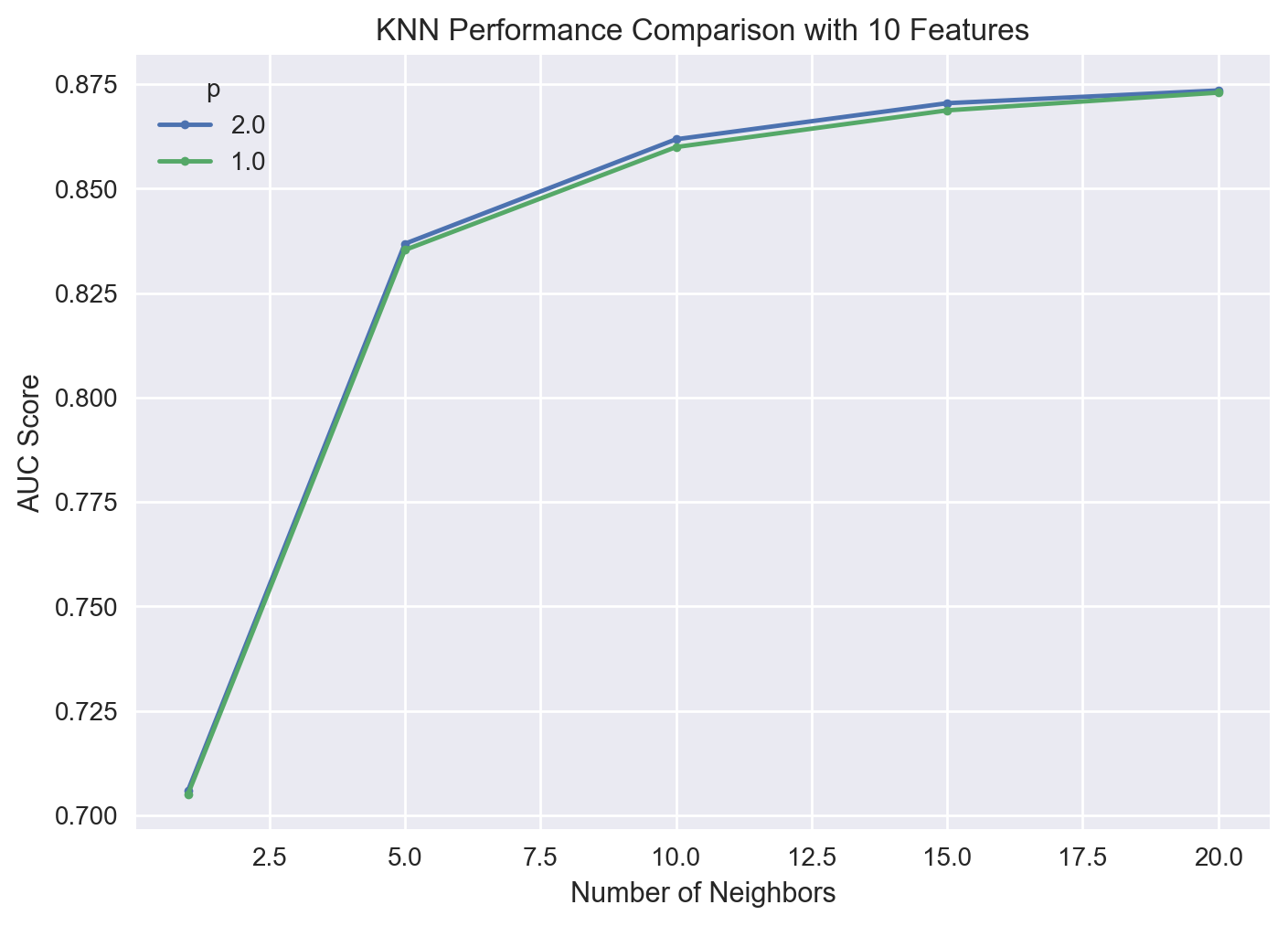
We observe that the difference between the hyperparameter combinations is not really much when conditioned on the number of features selected. Let’s visualize the results of the grid search corresponding to 10 selected features.
results_KNN_10_features = results_KNN[results_KNN['rfi_fs__n_features_'] == 10.0]
for i in results_KNN_10_features['knn__p'].unique():
temp = results_KNN_10_features[results_KNN_10_features['knn__p'] == i]
plt.plot(temp['knn__n_neighbors'], temp['mean_score'], marker = '.', label = i)
plt.legend(title = "p")
plt.xlabel('Number of Neighbors')
plt.ylabel("AUC Score")
plt.title("KNN Performance Comparison with 10 Features")
plt.show()
(Gaussian) Naive Bayes (NB)#
We implement a Gaussian Naive Bayes model. We optimize var_smoothing (a variant of Laplace smoothing) as we do not have any prior information about our dataset. By default, the var_smoothing parameter’s value is \(10^{-9}\) . We conduct the grid search in the logspace (over the powers of 10) sourced from NumPy. We start with 10 and end with \(10^{-3}\) with 200 different values, but we perform a random search over only 20 different values (for shorter run times). Since NB requires each descriptive feature to follow a Gaussian distribution, we first perform a power transformation on the input data before model fitting.
from sklearn.preprocessing import PowerTransformer
Data_sample_train_transformed = PowerTransformer().fit_transform(Data_sample_train)
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import RandomizedSearchCV
pipe_NB = Pipeline([('rfi_fs', RFIFeatureSelector()),
('nb', GaussianNB())])
params_pipe_NB = {'rfi_fs__n_features_': [10, 20, Data.shape[1]],
'nb__var_smoothing': np.logspace(1,-3, num=200)}
n_iter_search = 20
gs_pipe_NB = RandomizedSearchCV(estimator=pipe_NB,
param_distributions=params_pipe_NB,
cv=cv_method,
refit=True,
n_jobs=-2,
scoring='roc_auc',
n_iter=n_iter_search,
verbose=1)
gs_pipe_NB.fit(Data_sample_train_transformed, target_sample_train);
Fitting 5 folds for each of 20 candidates, totalling 100 fits
gs_pipe_NB.best_params_
{'rfi_fs__n_features_': 10, 'nb__var_smoothing': 0.9011018251665018}
gs_pipe_NB.best_score_
0.8799365392831007
The optimal NB yiels an AUC score of 0.878 (with 10 features) - slightly higher than that of KNN. At this point, we cannot conclude NB outperforms KNN. For this conclusion, we will have to perform a paired t-test on the test data as discussed further below.
results_NB = get_search_results(gs_pipe_NB)
results_NB.head()
| mean_score | std_score | max_score | min_score | rfi_fs__n_features_ | nb__var_smoothing | |
|---|---|---|---|---|---|---|
| 14 | 0.879937 | 0.002581 | 0.883908 | 0.875860 | 10.0 | 0.901102 |
| 0 | 0.878655 | 0.002820 | 0.882873 | 0.874479 | 10.0 | 2.171118 |
| 11 | 0.878568 | 0.002876 | 0.883613 | 0.875703 | 10.0 | 0.651734 |
| 17 | 0.878115 | 0.003046 | 0.882377 | 0.873137 | 10.0 | 0.391710 |
| 8 | 0.876028 | 0.003216 | 0.881826 | 0.871970 | 10.0 | 0.141499 |
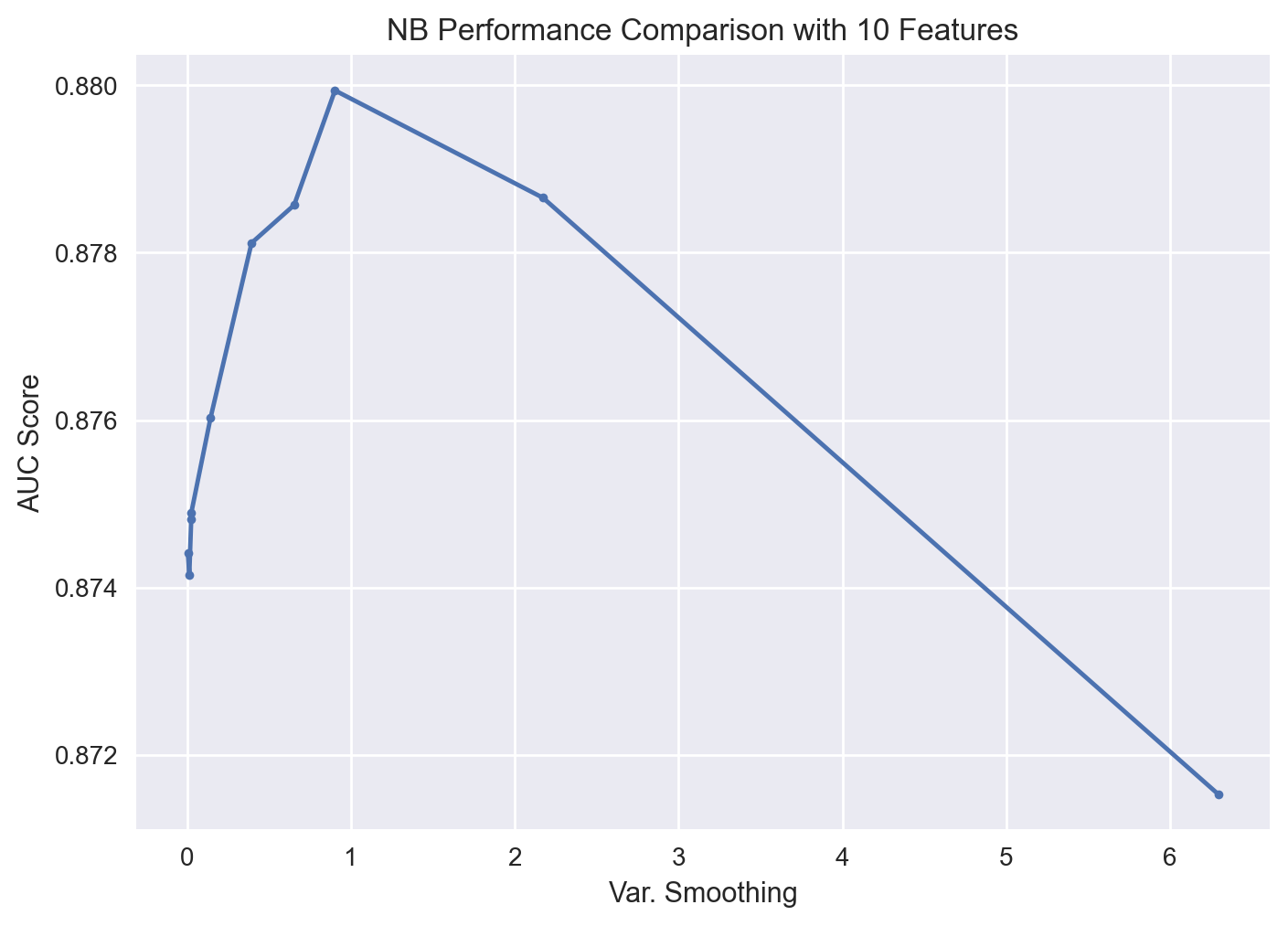
Let’s visualize the search results.
results_NB_10_features = results_NB[results_NB['rfi_fs__n_features_'] == 10.0].sort_values('nb__var_smoothing')
plt.plot(results_NB_10_features['nb__var_smoothing'], results_NB_10_features['mean_score'], marker = '.', label = i)
plt.xlabel('Var. Smoothing')
plt.ylabel("AUC Score")
plt.title("NB Performance Comparison with 10 Features")
plt.show()
Decision Trees (DT)#
We build a DT using gini index to maximize information gain. We aim to determine the optimal combinations of maximum depth (max_depth) and minimum sample split (min_samples_split).
from sklearn.tree import DecisionTreeClassifier
pipe_DT = Pipeline([('rfi_fs', RFIFeatureSelector()),
('dt', DecisionTreeClassifier(criterion='gini', random_state=111))])
params_pipe_DT = {'rfi_fs__n_features_': [10, 20, Data.shape[1]],
'dt__max_depth': [3, 4, 5],
'dt__min_samples_split': [2, 5]}
gs_pipe_DT = GridSearchCV(estimator=pipe_DT,
param_grid=params_pipe_DT,
cv=cv_method,
refit=True,
n_jobs=-2,
scoring='roc_auc',
verbose=1)
gs_pipe_DT.fit(Data_sample_train, target_sample_train);
Fitting 5 folds for each of 18 candidates, totalling 90 fits
gs_pipe_DT.best_params_
{'dt__max_depth': 5, 'dt__min_samples_split': 5, 'rfi_fs__n_features_': 10}
gs_pipe_DT.best_score_
0.8797384303576419
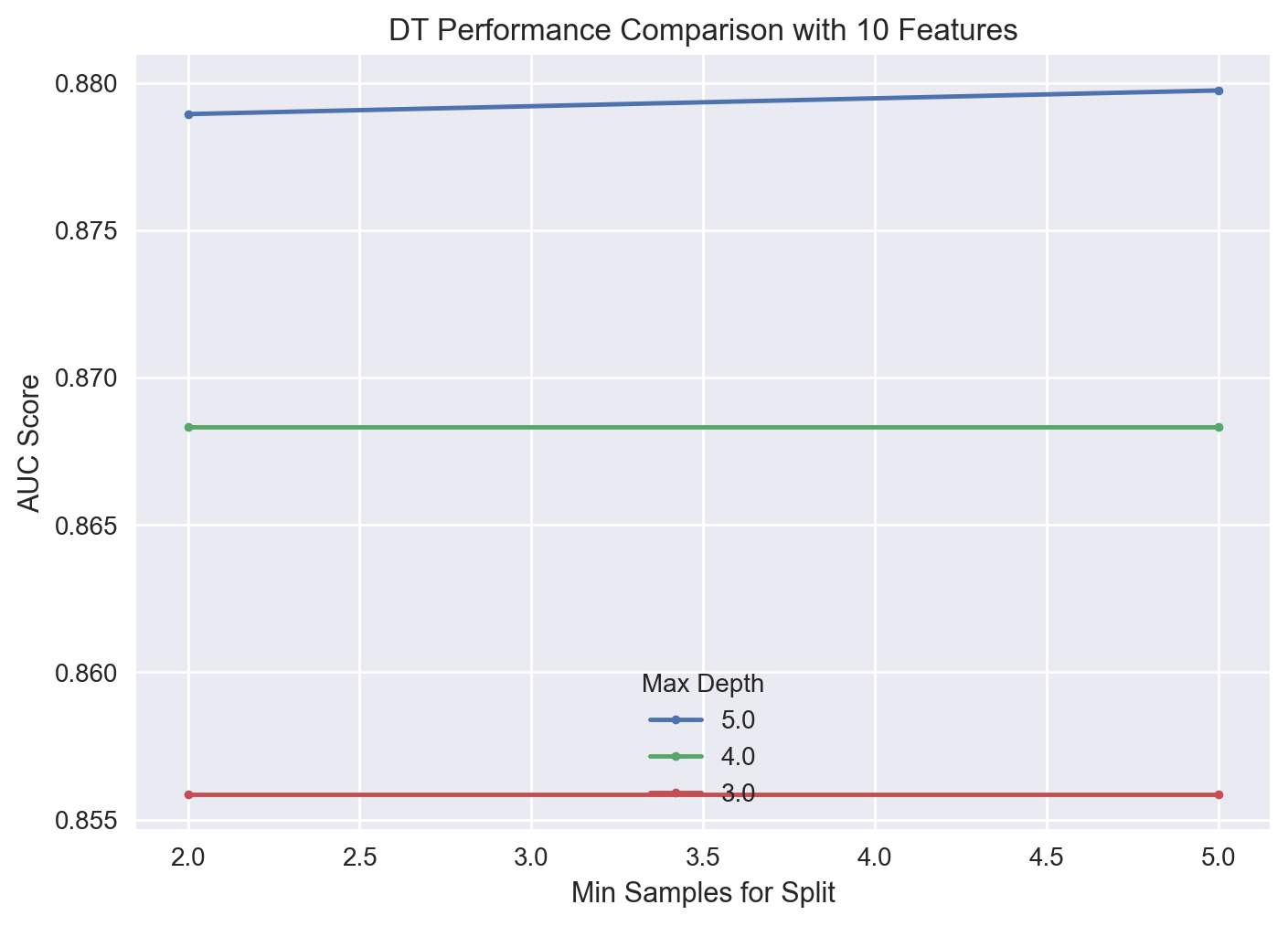
The best DT has a maximum depth of 5 and minimum split value of 2 samples with an AUC score of 0.881. A visualization of the search results is given below for 10 features.
results_DT = get_search_results(gs_pipe_DT)
results_DT_10_features = results_DT[results_DT['rfi_fs__n_features_'] == 10.0]
for i in results_DT_10_features['dt__max_depth'].unique():
temp = results_DT_10_features[results_DT_10_features['dt__max_depth'] == i]
plt.plot(temp['dt__min_samples_split'], temp['mean_score'], marker = '.', label = i)
plt.legend(title = "Max Depth")
plt.xlabel('Min Samples for Split')
plt.ylabel("AUC Score")
plt.title("DT Performance Comparison with 10 Features")
plt.show()
Further Fine Tuning#
We notice that the optimal value of maximum depth hyperparameter is at the extreme end of its search space. Thus, we need to go beyond what we already tried to make sure that we are not missing out on even better values. That is, we would like to see an “elbow shape” so that we can figure out where the improvement stops. For this reason, we try a new search as below.
params_pipe_DT2 = {'rfi_fs__n_features_': [10],
'dt__max_depth': [5, 10, 15],
'dt__min_samples_split': [5, 50, 100, 150, 200, 250]}
gs_pipe_DT2 = GridSearchCV(estimator=pipe_DT,
param_grid=params_pipe_DT2,
cv=cv_method,
refit=True,
n_jobs=-2,
scoring='roc_auc',
verbose=1)
gs_pipe_DT2.fit(Data_sample_train, target_sample_train);
Fitting 5 folds for each of 18 candidates, totalling 90 fits
gs_pipe_DT2.best_params_
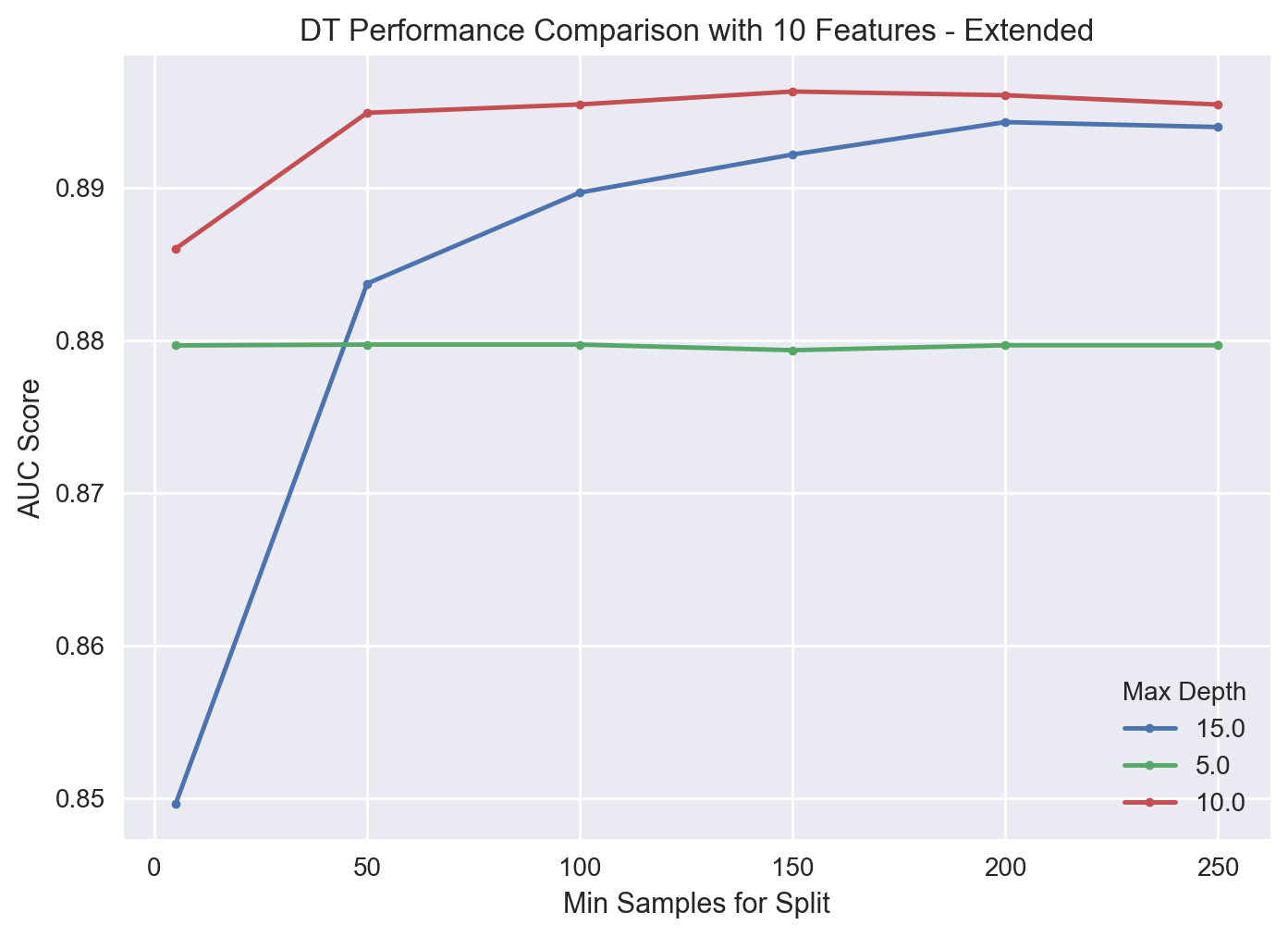
{'dt__max_depth': 10, 'dt__min_samples_split': 150, 'rfi_fs__n_features_': 10}
gs_pipe_DT2.best_score_
0.8962802058163899
As suspected, we can achieve slightly better results with the new search space.
results_DT = get_search_results(gs_pipe_DT2)
results_DT.head()
| mean_score | std_score | max_score | min_score | dt__max_depth | dt__min_samples_split | rfi_fs__n_features_ | |
|---|---|---|---|---|---|---|---|
| 9 | 0.896280 | 0.005781 | 0.901725 | 0.885281 | 10.0 | 150.0 | 10.0 |
| 10 | 0.896039 | 0.004196 | 0.900597 | 0.888148 | 10.0 | 200.0 | 10.0 |
| 8 | 0.895434 | 0.005571 | 0.901430 | 0.885672 | 10.0 | 100.0 | 10.0 |
| 11 | 0.895430 | 0.006171 | 0.901141 | 0.883781 | 10.0 | 250.0 | 10.0 |
| 7 | 0.894888 | 0.004542 | 0.901560 | 0.888698 | 10.0 | 50.0 | 10.0 |
We again observe that the cross-validated AUC score difference between the hyperparameter combinations is not really much. A visualization of the new search results is shown below.
results_DT_10_features = results_DT[results_DT['rfi_fs__n_features_'] == 10.0].sort_values('dt__min_samples_split')
for i in results_DT_10_features['dt__max_depth'].unique():
temp = results_DT_10_features[results_DT_10_features['dt__max_depth'] == i]
plt.plot(temp['dt__min_samples_split'], temp['mean_score'], marker = '.', label = i)
plt.legend(title = "Max Depth")
plt.xlabel('Min Samples for Split')
plt.ylabel("AUC Score")
plt.title("DT Performance Comparison with 10 Features - Extended")
plt.show()
Performance Comparison #
During the hyper-parameter tuning phase above, we used the 14K rows in our training data within a cross-validation framework and we determined the best hyper-parameter values for each of the three classifiers. For instance, for KNN, it turned out that the best set of hyper-parameter values is \(k=100\) and \(p=1\) with the best 10 features as selected by the RFI feature selection method.
What we would like to do now is to “fit” each tuned classifier (with the best set of hyper-parameter values) on the 6K rows in the test data in a cross-validated fashion to figure out which (tuned) classifier performs the best. This way, we would be measuring performance of the tuned classifiers on data that they did not “see” previously.
Since cross validation itself is a random process, we would like to perform pairwise t-tests to determine if any difference between the performance of any two (tuned) classifiers is statistically significant [1]. Specifically, we first perform 10-fold stratified cross-validation (without any repetitions) on each (tuned) classifier where we use the same seed in each of the three cross-validation runs. Second, we conduct a paired t-test for the AUC score between the following (tuned) classifier combinations:
KNN vs. NB,
KNN vs. DT, and
DT vs. NB.
Discussion#
Machine learning is as much as art as it is science. A proper performance comparison can be conducted in other ways (including the particular variant in here). On the other hand, what is “proper” depends on your objectives as well as the characteristics of the dataset you are working with.
For instance, in the case where amount of data available is especially a concern (say less than a few hundred observations), you might want to use 100% of the dataset as the training data during the hyper-parameter tuning phase, and also use 100% of the dataset as the test data during the performance comparison phase (this time using a different random seed). Here, you might want to opt for, say, 5-repeated 3-fold cross-validation. Apparently, this will be rather inappropriate as you would be using the same data in both of the tuning and performance comparison phases. However, since both phases involve cross-validation, effects of overfitting shall be quite limited. In particular, you might just decide that this is an acceptable trade-off given the lack of enough observations to work with.
Another popular performance comparison method calls for two nested cross-validation runs as follows: you resort to a train-test-split approach within an outer cross-validation framework, say 3-repeated 5-fold cross-validation, and you perform hyper-parameter tuning using a possibly different inner cross-validation scheme (say 5-fold with no repetitions). This variant is rather involved and we do not cover it in this tutorial.
from sklearn.model_selection import cross_val_score
cv_method_ttest = StratifiedKFold(n_splits=10, shuffle=True, random_state=111)
cv_results_KNN = cross_val_score(estimator=gs_pipe_KNN.best_estimator_,
X=Data_sample_test,
y=target_sample_test,
cv=cv_method_ttest,
n_jobs=-2,
scoring='roc_auc')
cv_results_KNN.mean()
0.8681593157808228
Data_sample_test_transformed = PowerTransformer().fit_transform(Data_sample_test)
cv_results_NB = cross_val_score(estimator=gs_pipe_NB.best_estimator_,
X=Data_sample_test_transformed,
y=target_sample_test,
cv=cv_method_ttest,
n_jobs=-2,
scoring='roc_auc')
cv_results_NB.mean()
0.8794885472721508
cv_results_DT = cross_val_score(estimator=gs_pipe_DT2.best_estimator_,
X=Data_sample_test,
y=target_sample_test,
cv=cv_method_ttest,
n_jobs=-2,
scoring='roc_auc')
cv_results_DT.mean()
0.8913256706832351
The above results indicate that the tuned DT classifier outperforms the other methods with a cross-validated test AUC of 0.891. However, the tuned KNN and NB classifiers are not far behind with AUC scores of 0.870 and 0.879 respectively. For this reason, we need to perform some statistical tests to check to see if this difference is indeed statistically significant.
Since we fixed the random state to be the same during cross-validation, all (tuned) classifiers were fitted and then tested on exactly the same data partitions, making our results “paired” in a statistical sense. So, we use the stats.ttest_rel function from the SciPy module to run the following paired t-tests.
from scipy import stats
print(stats.ttest_rel(cv_results_KNN, cv_results_NB))
print(stats.ttest_rel(cv_results_DT, cv_results_KNN))
print(stats.ttest_rel(cv_results_DT, cv_results_NB))
TtestResult(statistic=-2.9319621560781983, pvalue=0.01670362027015796, df=9)
TtestResult(statistic=8.985202004647071, pvalue=8.653748304042342e-06, df=9)
TtestResult(statistic=2.8844031427891266, pvalue=0.018048072872731125, df=9)
A p-value smaller than 0.05 indicates a statistically significant difference. Looking at these results, we observe that the difference between both DT/ KNN and DT/ NB pairs are indeed statistically significant (both p-values are smaller than 0.05). Thus, we conclude that at a 95% significance level, DT is statistically the best model in this competition (in terms of AUC) when compared on the test data.
Though we used AUC to optimize the algorithm hyper-parameters, we shall consider the following metrics to evaluate models based on the test set:
Accuracy
Precision
Recall
F1 Score (the harmonic average of precision and recall)
Confusion Matrix
These metrics can be computed using classification_report from sklearn.metrics. The classification reports are shown below.
pred_KNN = gs_pipe_KNN.predict(Data_sample_test)
Data_test_transformed = PowerTransformer().fit_transform(Data_sample_test)
pred_NB = gs_pipe_NB.predict(Data_test_transformed)
pred_DT = gs_pipe_DT2.predict(Data_sample_test)
from sklearn import metrics
print("\nClassification report for K-Nearest Neighbor")
print(metrics.classification_report(target_sample_test, pred_KNN))
print("\nClassification report for Naive Bayes")
print(metrics.classification_report(target_sample_test, pred_NB))
print("\nClassification report for Decision Tree")
print(metrics.classification_report(target_sample_test, pred_DT))
Classification report for K-Nearest Neighbor
precision recall f1-score support
<=50k 0.85 0.92 0.89 4471
>50k 0.71 0.53 0.60 1529
accuracy 0.82 6000
macro avg 0.78 0.73 0.74 6000
weighted avg 0.81 0.82 0.81 6000
Classification report for Naive Bayes
precision recall f1-score support
<=50k 0.87 0.90 0.89 4471
>50k 0.68 0.61 0.64 1529
accuracy 0.83 6000
macro avg 0.78 0.76 0.77 6000
weighted avg 0.82 0.83 0.82 6000
Classification report for Decision Tree
precision recall f1-score support
<=50k 0.86 0.94 0.90 4471
>50k 0.77 0.56 0.65 1529
accuracy 0.85 6000
macro avg 0.82 0.75 0.78 6000
weighted avg 0.84 0.85 0.84 6000
The confusion matrices are given below.
from sklearn import metrics
print("\nConfusion matrix for K-Nearest Neighbor")
print(metrics.confusion_matrix(target_sample_test, pred_KNN))
print("\nConfusion matrix for Naive Bayes")
print(metrics.confusion_matrix(target_sample_test, pred_NB))
print("\nConfusion matrix for Decision Tree")
print(metrics.confusion_matrix(target_sample_test, pred_DT))
Confusion matrix for K-Nearest Neighbor
[[4135 336]
[ 725 804]]
Confusion matrix for Naive Bayes
[[4030 441]
[ 592 937]]
Confusion matrix for Decision Tree
[[4219 252]
[ 667 862]]
Suppose we are a tax agency and we would like to detect individuals earning more than USD 50K. Then we would choose recall as the performance metric, which is equivalent to the true positive rate (TPR). In this context, NB would be the best performer since it produces the highest recall score for incomes higher than USD 50K. The confusion matrices are in line with the classification reports. This is in contrast to our finding that DT is statistically the best performer when it comes to the AUC metric.
Limitations and Proposed Solutions #
Our modeling strategy has a few flaws and limitations. First, ours was a black-box approach since we preferred raw predictive performance over interpretability. In the future, we could consider a more in-depth analysis regarding the feature selection & ranking process as well as our choices for the hyper-parameter spaces.
Second, we utilized a blanket power transformation on the training data when building the NB, ignoring the dummy features within the dataset. This might partially explain the poor performance of the NB when evaluated on the test set. A potential solution is to build a Gaussian NB and a Bernoulli NB separately on the numerical and dummy descriptive features respectively. Then we can compute a final prediction by multiplying predictions from each model since NB assumes inter-independence conditioned on the value of the target feature.
Third, we only worked with a small subset of the full dataset for shorter run times, both for training and testing. Since data is always valuable, we could re-run our experiments with the entire data while making sure that the train and test split is performed in a proper manner.
The DT classifier statistically outperforms the other two models. Therefore, we can perhaps improve it by further expanding the hyper-parameter search space by including other parameters of this classification method. Furthermore, we can consider random forests and other ensemble methods built on trees as potentially better models.
Summary #
The Decision Tree model with 10 of the best features selected by Random Forest Importance (RFI) produces the highest cross-validated AUC score on the training data. In addition, when evaluated on the test data (in a cross-validated fashion), the Decision Tree model again outperforms both Naive Bayes and k-Nearest Neighbor models with respect to AUC. However, the Naive Bayes model yields the highest recall score on the test data. We also observe that our models are not very sensitive to the number of features as selected by RFI when conditioned on the values of the hyper-parameters in general. For this reason, it seems working with 10 features is preferable to working with the full feature set, which potentially avoids overfitting and results in models that are easier to train and easier to understand.
References#
Lichman, M. (2013). UCI Machine Learning Repository: Census Income Data Set [online]. Available at https://archive.ics.uci.edu/ml/datasets/adult [Accessed 2021-06-14]